![]()
看网课的一些笔记 📝
影响性能的几个方面 🔰
- 服务器硬件 CPU 内存 I/O子系统 网络
- 服务器操作系统
- 数据库存储引擎的选择
- 数据库参数配置 => 影响巨大
- 数据库结构设计和SQL语句 => 慢查询
数据库结构优化 🔧
目的:
- 减少数据冗余
- 尽量避免数据维护中出现更新, 插入, 删除异常
- 插入异常: 表中某个实体随另一个实体存在
- 更改表中某个实体的单独属性时, 需要对多行进行更新
- 删除b表中的某一实体会导致其他实体的消失
逻辑设计
范式化:
- 可以尽量减少数据冗余 😊
- 更新操作比反范式化快 😊
- 表通常比反范式化小 😊
- 对于查询需要对多个表进行关联 😔
- 更难进行索引优化 😔
反范式化:
- 可以减少表的关联 😊
- 更好进行索引优化 😊
- 存在数据冗余和数据维护异常 😔
- 对数据的修改需要更多成本 😔
在范式化基础上适当反范式化
物理设计
选择合适的存储引擎: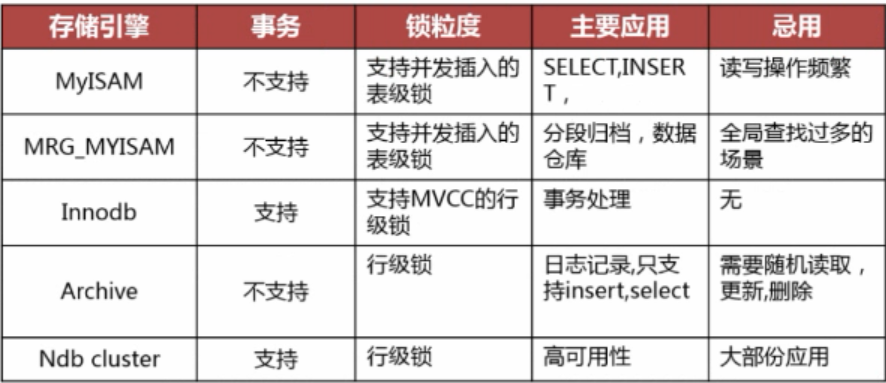
为表中的字段选择合适的数据类型:
当一个列可以选择多种数据类型时, 应该优先考虑数字类型, 其次是日期或二进制类型, 最后是字符类型. 对于相同级别的数据类型, 应该优先选择占用空间小的数据类型.
- 财务相关数据应选择decimal
- varchar和char的宽度是以字符(而不是字节)为单位, 如UTF-8一个字符占用3个字节
- varchar不定长, 适用场景:
- 字符串列的最大长度比平均长度大很多
- 字符串列很少被更新
- 使用了多字节字符集(UTF-8)存储字符串
- char定长, 适用场景:
- 适合存储长度近似的值(md5, 身份证)
- 短字符串(性别)
- 经常更新的字符串列
日期类型:
- datatime: YYYY-MM-DD HH:MM:SS[.fraction]
与时区无关, 占用8个字节
范围: 1000-01-01 00:00:00 – 9999-12-31 23:59:59 - timestamp: YYYY-MM-DD HH:MM:SS[.fraction]
时区有关, 时间戳, 占用4个字节 在行的数据修改时可以自动修改timestamp列的值
范围: 1970-01-01 00:00:00 – 2038-01-19 23:59:59 - date: YYYY-MM-DD
可以用date存储日期, 只要3个字节
可以用日期时间函数进行日期间的计算
范围: 1000-01-01 – 9999-12-31 - time: HH:MM:SS[.fraction]
不要用字符串类型存储日期时间
如何为InnoDB选择逐渐:
- 主键应该尽可能的小
- 主键应该是顺序增长的
- InnoDB的主键和业务主键可以不同
数据库索引优化 📌
为什么使用索引:
- 大大减少了存储引擎需要扫描的数据量
- 进行排序时避免使用临时表
- 可以把随机I/O变为顺序I/O
索引不是越多越好:
- 会增加写操作的成本
- 会增加查询优化器的选择时间
B-tree索引
特点:
- 以B+树结构存储数据
- 加快数据查询速度
- 适合进行范围查找
什么时候用到 😊
- 等值查询
user_name=”bxy” - 匹配最左前缀查询
联合索引(user_name, id) 查询条件为user_name列时, 会使用该联合索引 - 匹配列前缀查询
user_name like ‘bx%’ - 范围查找
id > 10 and id < 100 - 精确匹配左前列并范围匹配另外一列
精确匹配user_name 并范围查询id - 只访问索引的查询
只需访问索引, 无需访问数据行(无需回表操作) 即覆盖索引
使用限制 😔
- 如果不是按照索引最左列开始查找, 则无法使用索引
联合索引(user_name, id) 查询条件为id列时, 无法使用该联合索引 - 使用索引时不能跳过索引中的列
联合索引(user_name, id, role) 查询条件包含user_name和role 只有user_name会用到该联合索引 - not in 和 <> 操作无法使用索引
- 如果查询中有某个列的范围查询, 则其右边的所有列都无法使用索引
联合索引(id, role, …) id使用范围查询, 则其右边的列都无法使用索引
Hash索引
特点:
- 基于hash表实现
- 只能用在等值查询中
- hash索引中的所有列, 存储引擎都会每一行计算一个hash码, hash索引中存储的是hash码
限制:
- hash索引必须进行二次查找
索引中没有保存字段的值, 先通过hash索引找到对应的行, 再从行中读取字段 - 无法用于排序
- 不支持部分索引查找也不支持范围查找
- hash码的计算可能存在hash冲突, 不适合用用在选择性差的列上(如性别, 只有男和女)
索引优化策略
- 索引列上不能使用函数或表达式

- 注意控制前缀索引的长度和索引列的选择性
- 建立联合索引
- 经常会被使用到的列优先
- 选择性高的列优先
- 宽度小的列优先
- 使用索引覆盖
利用索引优化锁:
- 索引可以减少锁定的行数
- 索引可以加快处理速度, 同时也加快锁的释放
删除重复和冗余索引:
- primary key(id),
unique key(id),index(id) index(a), index(a, b)- primary key(id),
index(a, id)
SQL查询优化 🔎
获取有性能问题的SQL途径:
- slow_query_log 启动慢查询日志
常用慢查询日志分析工具: mysqldumpslow pt-query-digest - 通过information_schema中的processlist表来实时获取有性能问题的SQL
确定查询处理各个阶段消耗的时间:
- 使用profile
- 使用performance_schema
特定的SQL查询优化:
- 修改大表的表结构 使用pt-online-schema-change
- 如何优化not in和<>查询

- 使用汇总表优化查询
- 待汇总…
数据库分库分表 📦
分库分表可以分担主数据库的写负载, 主从复制可以分担主数据库的读负载
不到万不得已不用考虑数据库分片
待汇总…
MySQL主从复制 💾
复制解决了什么问题:
- 实现在不同服务器上的数据分布
- 实现数据读取的负载均衡
- 增强了数据的安全性
- 实现数据库高可用和故障切换
- 实现数据库在线升级
二进制日志
二进制日志binlog是MySQL服务层日志, 记录了所有对MySQL数据库的修改事件, 包括CRUD和对表结构的修改事件
二进制日志的格式:
- 基于段的格式 binlog_format=STATEMENT 记录的是SQL语句
- 日志记录量相对较小, 节约磁盘及网络I/O 😊
只对一条记录修改或插入, row格式所产生的日志量小于段产生的日志量 - 必须要记录上下文信息, 保证语句在服务器上执行结果和在主服务器上相同 😔
特定函数如UUID(), user() 这样非确定性函数还是无法复制
可能造成MySQL复制的主备服务器数据不一致
- 日志记录量相对较小, 节约磁盘及网络I/O 😊
- 基于行的日志格式 binlog_format=ROW (version > 5.7 default) 记录的是修改记录行的信息
- 可以避免MySQL复制中出现的主从不一致问题 😊
对每一行数据的修改比基于段的复制高效 - 记录日志量较大 😔
binlog_row_image=[FULL | MINIMAL | NOBLOB]
- 可以避免MySQL复制中出现的主从不一致问题 😊
- 混合日志格式 binlog_format=MIXED
- 根据SQL语句由系统决定在段or行的日志格式中选择
- 数据量的大小由所执行的SQL语句决定
二进制日志格式对复制的影响
基于SQL语句的复制(SBR)
优点:
- 生成的日志量少, 节约网络传输I/O
- 不强制要求主从数据库的表定义完全相同
- 相比于基于行的复制方式更为灵活
缺点:
- 对于非确定性事件, 无法保证主从复制数据一致性
- 对于存储过程, 触发器, 自定义函数进行的修改也可能造成数据不一致
- 相比于基于行的复制方式在从库上执行需要更多的行锁
基于行的复制(RBR) 👍
优点:
- 可以应用于任何SQL的复制包括非确定性函数, 存储过程等
- 可以减少从库锁的使用
缺点:
- 要求主从数据库的表结构相同, 否则可能会中断复制
- 无法在从库上单独执行触发器
MySQL复制工作方式
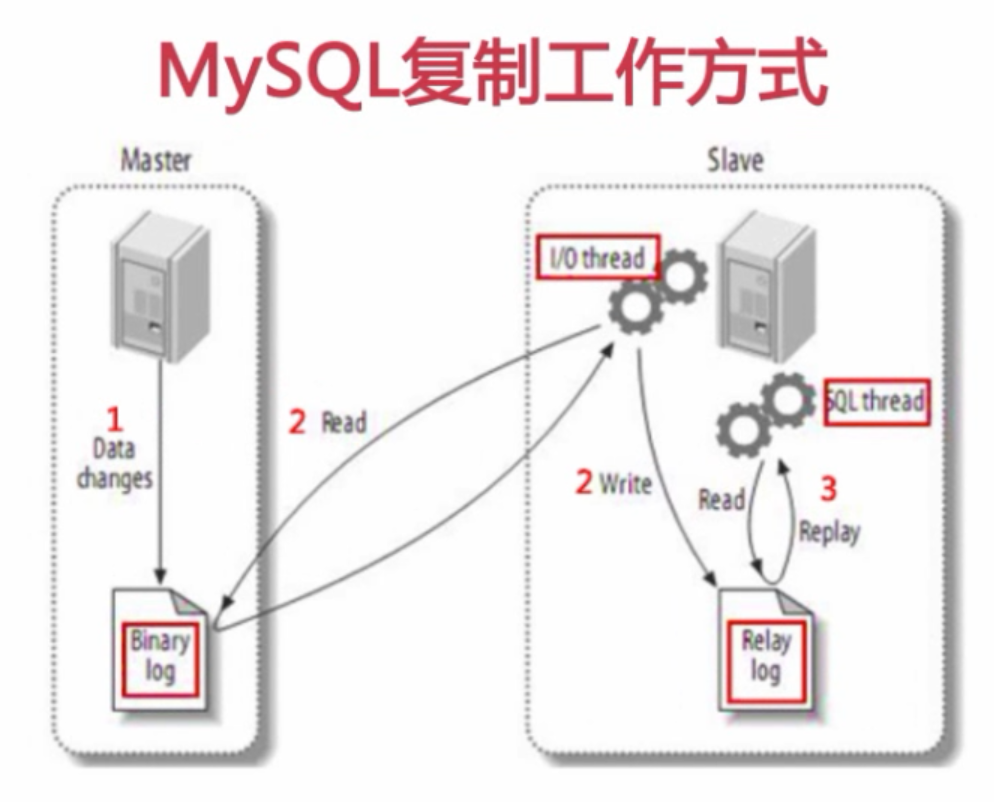
- 主服务器将变更写入二进制日志(需先开启binlog, 否则再开启要重启数据库服务器)
- 从服务器读取主服务器的二进制日志变更并写入到relay_log中
在从服务器上启动一个工作线程(I/O线程)与主库建立客户端连接, 在主库上启动二进制转储线程(binlogdump), I/O线程就通过binlogdump读取主库的binlog中的事件
根据从什么位置开始读取binlog, 可以分为- 基于日志点的复制
- 基于GTID的复制
- 从服务器读取relay_log中的事件, 在从库上重放(由SQL线程完成)
MySQL复制性能优化
影响主从延迟的因素
- 主库写入二进制日志的时间 => 控制主库的事务大小, 分割大事务
- 二进制日志传输时间 => 使用MIXED日志格式或设置set binlog_row_image=minimal
- 默认情况只有一个SQL线程, 主库上b并发的修改在从库上变成了串行 => 使用多线程复制